

こんにちは、Supabaseって便利ですよね。Firebaseの代替を狙っているだけあり、無料でDBや会員管理、ストレージなどFirebaseにも負けず便利です。ほとんどの場合は無料で十分だと思います。
しかし、無料で1つだけ物足りない点があります。それがDBのバックアップです。残念ながらバックアップ機能は有料で月$25以上を払わないといけません。そこで今回はPythonでSupabaseのバックアップ/リストアを行うスクリプトを書いたので記事にまとめておこうと思います。
私の用途ではそのうち容量も足りなくなる見込みなので有料プランに変更する見込みなので、みなさんも一時的なものとして見てみてください。
環境準備
本記事ではバックアップの処理をPythonで書くので、その環境を用意します。今回はDocker上のPythonで雑に用意しようと思います。ちなみにここで書くDocker設定は他のスクリプトを書いたときのものを流用しているため、不要な設定などがあるかもしれないので参考までにご覧ください。
というわけでDockerに必要なファイルを用意します。ディレクトリの連携も雑に対応していくためdocker-compose.ymlと DockerfileそしてPythonでインストールするライブラリを記述するrequirements.txtを用意します。正直なところ必要なライブラリはSupabaseだけなのでテキストファイルを用意するっ必要もないですが、おまけです。
version: '3'
services:
python:
container_name: supabase-python-backup
build: .
volumes:
- .:/workspace
tty: trueFROM python:3.9.10
RUN apt-get update
WORKDIR /workspace
COPY ./requirements.txt ./
RUN pip install --no-cache-dir -r requirements.txtsupabase==0.3.0ちなみにSupabaseのPython向けライブラリは、現在まだベータ版とのことなので、新しいバージョンが出た際は指定バージョンを変更するようにしてください。
これらと次に紹介するスクリプトを同じディレクトリに設置して下準備完了です。今回はDocker環境で動かすためにこのようにしましたが、supabaseのライブラリが動けば何でも大丈夫です(直接叩けばライブラリすら不要です)。
APIキーを準備
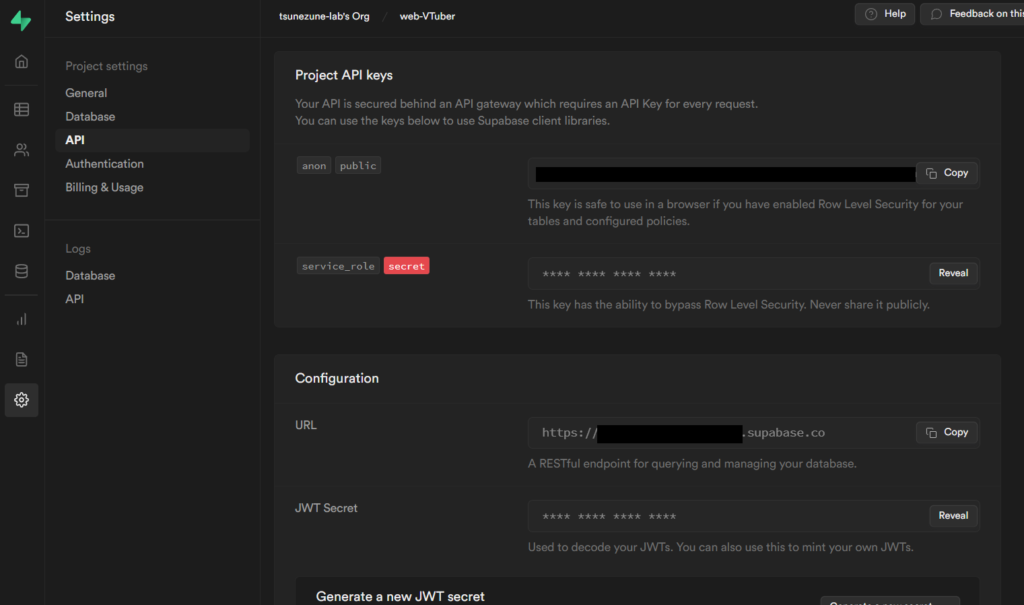
次にSupabaseの操作を行うためのAPIキーを取得します。 Supabaesの管理画面にログインしてメニューのSettings→APIの項目からProject API keysのservice_roleとConfigurationのURLをメモしておいてください。

スクリプトの用意
さて、次は本題のスクリプトです。今回は雑にクラスにまとめているのでそれだけ掲載しておこうと思います。git?知らない子ですね。
import os
import shutil
import pickle
from supabase import create_client, Client
os.environ['OAUTHLIB_INSECURE_TRANSPORT'] = '1'
class supabaseBackup():
def __init__(self, supabase_api_url:str, supabase_api_key:str):
self._supabase: Client = create_client(supabase_api_url, supabase_api_key)
# エクスポート出力先ディレクトリ
self._FILE_DIR = './backup'
# Supabaseで設定している1回のクエリの取得件数上限
self._MAX_ROWS = 1000
def _save(self, table_name:str, data:any):
""" データをファイル出力する
Args:
table_name (str): 出力するテーブル名
data (any): 出力するデータ
"""
with open(f'{self._FILE_DIR}/backup-{table_name}.pkl', 'wb') as f:
pickle.dump(data, f)
def _load(self, table_name:str):
""" ファイルからテーブルのデータをインポートする
Args:
table_name (str): インポートするテーブル名
Return:
any: ファイルから読み込んだデータ
"""
with open(f'{self._FILE_DIR}/backup-{table_name}.pkl', 'rb') as f:
return pickle.load(f)
def copy_to_date_directory(self):
""" ディレクトリに保存されているpklファイルを日付ディレクトリに移動する
"""
import datetime
date = datetime.datetime.today().strftime("%Y%m%d%H%M%S")
dir = f'{self._FILE_DIR}/{date}'
os.makedirs(dir, exist_ok=True)
# 既存の pkl ファイルを日付ディレクトリにコピーする
import glob
for p in glob.glob(f'{self._FILE_DIR}/*.pkl'):
shutil.copy(p, dir)
def supabase_backup_table(self, table_name:str):
""" Supabase の指定テーブルのデータをすべてファイルに出力する
Args:
table_name (str): 出力するテーブル名
"""
i = 0
rows = []
while True:
offset = self._MAX_ROWS * i
data = self._supabase\
.table(table_name)\
.select('*')\
.limit(1000, start=offset)\
.execute()\
.data
if len(data) == 0:
break
else:
i += 1
rows += data
self._save(table_name, rows)
def supabase_restore_table(self, table_name:str, import_to_table_name:str = ''):
""" Supabase の指定テーブルにファイルからデータをインポートする
Args:
table_name (str): インポートするテーブル名
import_to_table_name (str): インポート先のテーブル名(ステージング環境テーブルにインポートする場合に使用する)
"""
if import_to_table_name == '':
import_to_table_name = table_name
import_data = self._load(table_name)
for i in range(0, len(import_data), self._MAX_ROWS):
self._supabase.table(import_to_table_name).insert(import_data[i:i+self._MAX_ROWS]).execute()
def supabase_clean(self, table_name:str):
""" Supabase の指定テーブルのデータを空にする
Args:
table_name (str): データを空にするテーブル名
"""
self._supabase.table(table_name).delete().execute()さて、コードを書いてしまったのでこれ以上書くことはないのですが、実装時に少しハマったところは取得件数上限が1000件なので、それ以上にレコードがある場合はそれだけクエリを実行しなくてはいけないという点です。しかし、クエリ結果のDLは制限なしというのは嬉しいですね。
使ってみる
最後にこのスクリプトを使ってみようと思います。上記でクラスの定義はできているので、使うだけです。
if __name__ == '__main__':
# Supabase
SUPABASE_API_URL: str = 'TODO Supabase_URL https://xxxxxxxxxxxxxxxxxxxxxxxxx.supabase.co'
SUPABASE_API_KEY: str = 'TODO SUpabase_KEY xxxxxxxxxxxxxxxxxxx......xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
backup = supabaseBackup(SUPABASE_API_URL, SUPABASE_API_KEY)
# エクスポート
backup.supabase_backup_table('TODO エクスポートするテーブル名')
# 保存されているバックアップファイルを日付付きのディレクトリにコピー
backup.copy_to_date_directory()
# ステージング環境のテーブルをクリア
backup.supabase_clean('TODO インポートするテーブル名')
# ステージング環境にリストア
backup.supabase_restore_table('TODO インポートするテーブル名', 'TODO インポート先のテーブル名')$ docker exec -it supabase-python-backup python main.pyこのスクリプトで、SupabaseのDBからデータを全件エクスポートして、インポートするという一連の流れが実行されます。設定値をベタ書きするなとか、バックアップファイルの扱い方とかツッコミ所はありますが、私の要望は満たしてくれているので一旦おいておきます。
終わりに
というわけで、無料プランのままバックアップを取る方法を書いてみました。もうDBの容量が8割くらいまで行っているのですぐ有料バックアップを使えるようになりますが、無料で使えるうちは使い倒してやりますよ!









